- Insert 語法中並無 where 的搜尋條件,因此不會使用到相關索引的 "seek" 或 "scan",相對不會產生成本。但需針對所有 "Index",新增該資料的 "鍵值資料行"與相關資料行
- CASE 1



insert into tbPerson01 (BusinessEntityID, PersonType, FirstName, LastName)
values (300, 'EM', 'Dale', 'Chen');
insert into tbPerson02 (BusinessEntityID, PersonType, FirstName, LastName)
values (300, 'EM', 'Dale', 'Chen');
- Result:
- heap 與 clustered 資料表進行 Insert 操作,並不會造成不同操作成本,即使大量的新增,成本都是相同
- CASE 2
- index 造成額外索引維護成本
- 兩個相同為 Clustered 資料表,但其中一個有較多 NonClustered 索引數的資料表是否會產生額外成本
- 資料庫使用 Adventure Works for SQL Server 2012 的資料表 Person.Person 創建 2 個 table 如下
- tbPerson01
- unique Clustered index (BusinessEntityID)
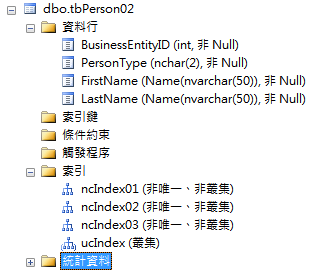
- tbPerson02:
- unique Clustered index (BusinessEntityID)
- NonClustered index (PersonType)
- NonClustered index (FirstName)
- NonClustered index (LastName)
- 查詢
insert into tbPerson01 (BusinessEntityID, PersonType, FirstName, LastName)
values (300, 'EM', 'Dale', 'Chen');
insert into tbPerson02 (BusinessEntityID, PersonType, FirstName, LastName)
values (300, 'EM', 'Dale', 'Chen');
- Result:
- 當資料表包含多個 "index" 時,"insert" 就必需同時維護所有 "index" 資料,所以會產生額外的維護成本
- 執行成本估算方法如下
- "Heap" 或 單個"Clustered",維護成本相同
- "Heap" 或單個"Clustered" 加 N個 "NonClustered",可視為 1 + N 個 "index" 維護成本
- REF:


















































{kind=link}