- 同時使用多個 "NonClustered Index" 的 Index Intersection 觀察
- 一個查尋如何同時使用多個索引
- 如果經常會同時使用到多個條件篩選,是否可考慮多創建幾個 "Index"
- 資料庫使用 Adventure Works for SQL Server 2012 的資料表 Production.Product 產生 1 個資料表,但包含 "Clustered " 與多個 "NonClustered Index"
- clIndex:Clustered (BusinessEntityID)
- ncIndex01:NonClustered Index (FirstName)
- ncIndex02:NonClustered Index (LastName)
- ncIndex03:NonClustered Index (PersonType)
select BusinessEntityID, FirstName, LastName
from tbPerson
where FirstName = 'Mae' and LastName = 'Black' and PersonType = 'SC'
select BusinessEntityID, FirstName, LastName
from tbPerson with(index(ncIndex01, ncIndex02, ncIndex03))
where FirstName = 'Mae' and LastName = 'Black' and PersonType = 'SC'
- 查詢結果
- FirstName = 'Mae' 符合筆數為 2 筆
- LastName = 'Black' 符合筆數為 35 筆
- PersonType = 'SC' 符合筆數為 753 筆
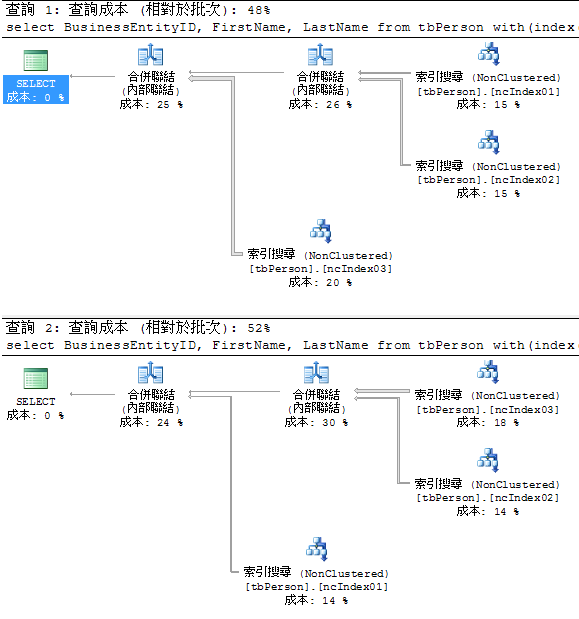
- 因此 Query Optimizer 採用 ncIndex01 與 ncIndex02,而 PersonType 使用 clIndex 而非 ncIndex03,使得強制使用 ncIndex03 成本較高
select BusinessEntityID, FirstName, LastName
from tbPerson with(index(ncIndex01, ncIndex02, ncIndex03))
where FirstName = 'Mae' and LastName = 'Black' and PersonType = 'SC'
select BusinessEntityID, FirstName, LastName
from tbPerson with(index(ncIndex03, ncIndex02, ncIndex01))
where FirstName = 'Mae' and LastName = 'Black' and PersonType = 'SC'
- 查詢結果
- 同樣強制使用三個所引情況
- "資料表提示" 後的 index 放置順序,如果依據資料量較少至多的順序放置 (ncIndex01, ncIndex02, ncIndex03),查詢成本會較低
- Result:
- where 條件篩選,如使用多個 "資料行",且所查詢結果資料量不大時,可將篩選的 "資料行" 建立 "NonClustered Index"
- 每個條件所查詢資料量不大,Query Optimizer 將會採用 "NonClustered Index",此可提升查詢效率
- REF:







沒有留言:
張貼留言