進階 "索引" 運用技巧
"NonClustered Index" 比較
- NonClustered Index (非叢集索引)
- 適用時機:
- 涵蓋範圍:"鍵值資料行" 外,包括 "row locator" 下列其中之一
- 基於 "Heap",資料行包括 "鍵值資料行" (Key Column) 與 Row ID (RID)
- 基於 "Clustered Index",資料行包括本身索引 "鍵值資料行" (Key Column) 與 "Clustered Index" 的 "鍵值資料行" (Key Column)
- 語法:
create (unique) NonClustered index ...
on ...
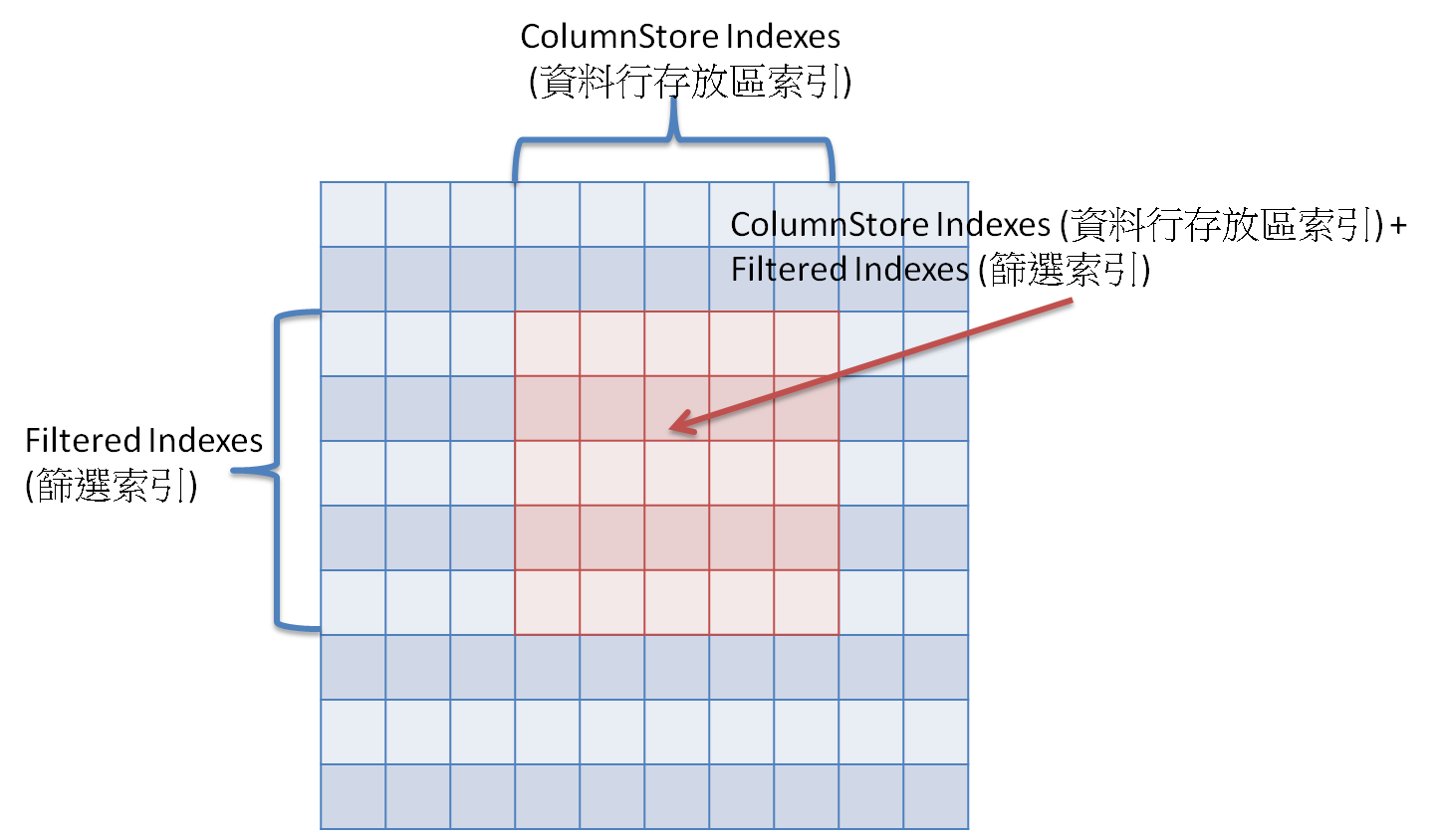
- ColumnStore Indexes (資料行存放區索引)
- 特性:
- 縱向 "資料行" 主要思考,除了一般 "NonClustered Index" 所具有 "資料行" 外,可額外加入 "非鍵值資料行" 避免額外的 "查閱" (lookup) 成本
- ColumnStore Indexes (資料行存放區索引),像似資料行較少的 "Clustered Index"
- 適用時機:
- 避免額外使用 "查閱" 成本,將常用 "資料行" 直接利用 include 方式加入 "索引" 提高查詢效益
- 涵蓋範圍:
- "鍵值資料行" 與 "row locator" 外,可透過 include 方式加入其它常用 "資料行"
- 語法:
create (unique) NonClustered index ...
on ...
include (...)
- Filtered Indexes (篩選索引)
- 特性:
- 縱向 "資料列" 主要思考,除了一般 "NonClustered Index" 所具有 "資料行" 外,可真對 "資料列" 進行篩選",讓索引變得更小,降低查詢成本
- Filtered Indexes (資料行存放區索引),像似資料列較少的 "NonClustered Index"
- 適用時機:
- 資料表的大部份資料屬於歷史性資料,而大部份查尋真對近期資料,建議使用此方式提升查詢效率
- 涵蓋範圍:
- "資料行" 範圍如一般 "NonClustered index","資料列" 範圍比一般的 "NonClustered index" 少很多
- 語法:
create (unique) NonClustered index ...
on ...
where ...
- ColumnStore Indexes (資料行存放區索引) + Filtered Indexes (篩選索引)
- 特性:
- 同時兼顧 "資料行" 與 "資料列",像輕量型 "Clustered Index"
- 適用時機:
- 如同 ColumnStore Indexes (資料行存放區索引) 與 Filtered Indexes (篩選索引)的交集
create (unique) NonClustered index ...
on ...
include (...)
where ...
- Indexed View (索引檢視表):或稱 Materialized Views (具體檢視表)
- 特性:
- 一般索引只能真對單個資料表或檢視表來建立
- "檢視表" 的特性可同時參考很多資料表
- Indexed View (索引檢視表) 同時兼具 "檢視表" 特性與 "索引" 功能,會將 join 後的資料儲存在儲存體內
- 適用時機:
- 查詢經常使用特定幾個資料表 join 與計算功能,可用 Indexed View (索引檢視表) 提升查詢效率
- 涵蓋範圍:
- 兼具 "資料行" 與 "資料列" 篩選外,可跨多個資料表 (join) 與事先計算功能
注意慎選所需建立的索引種類,索引可代來很多查詢效益,但建立很多不同的索引會造成,使用掉非常多儲存空間,也會使 insert / update / delete 作業效能下降
沒有留言:
張貼留言